背景信息#
Algolia DocSearch 是一个开源的搜索框,可以免费为其他开源软件或服务提供支持。在维护 Rancher 中文文档的时候,我碰到了一个 Algolia DocSearch 搜索框失效的问题。作为一个没有太多技术背景和代码经验的文档工程师,我花了很久才把这个问题搞清楚。后来在面试其他公司的时候,恰好他们也有这个问题,就提了个 issue,给了一些排查思路。面试都过了,但是最后 offer 审批慢了一些,就没去。这个问题在 Rancher 中文文档的代码库 wiki 里面也有记录,但当时图快,写得比较粗糙,还是希望静下来仔细写一下的。
问题现象#
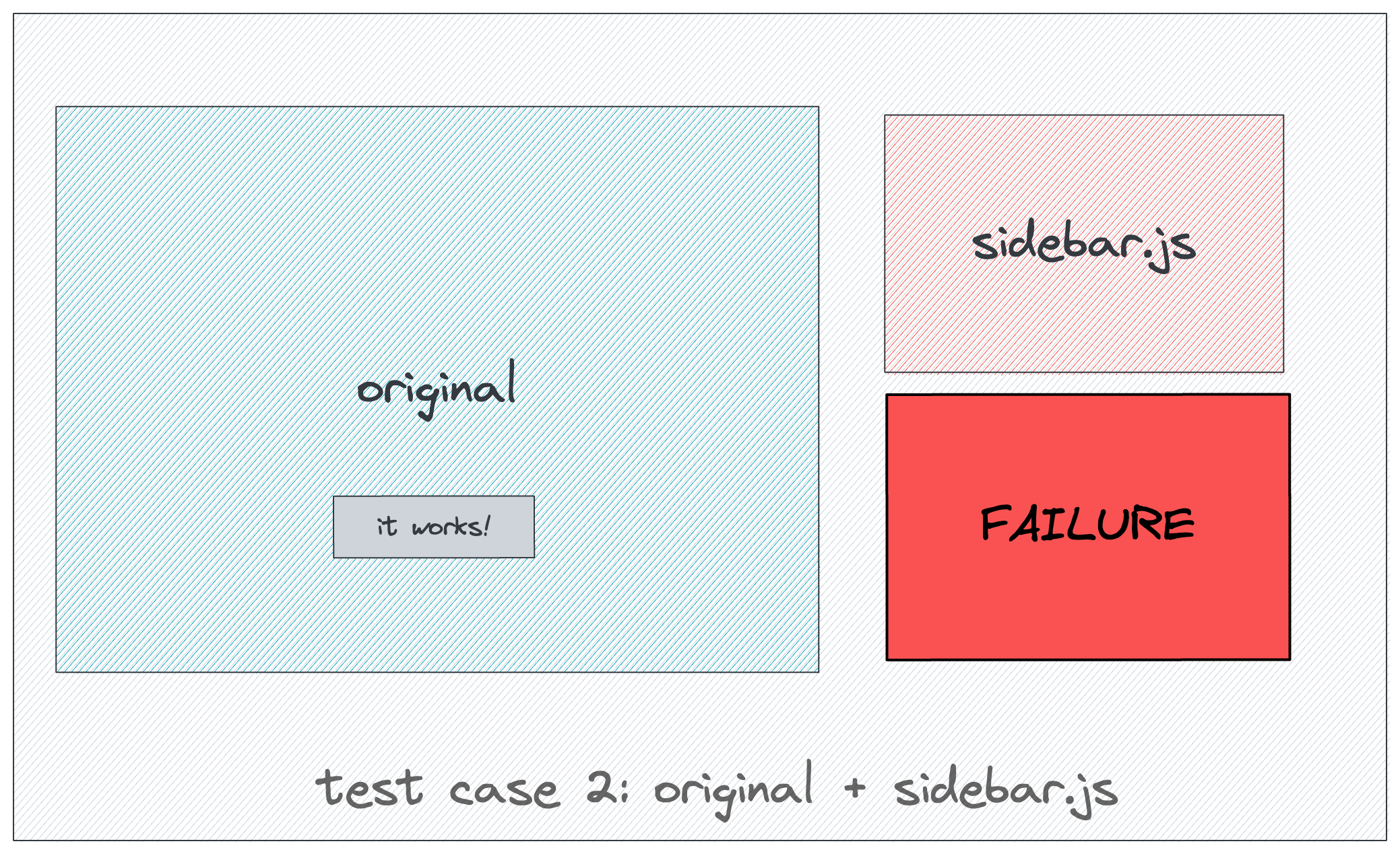
通过 Rancher 文档页面的搜索框输入关键字进行搜索时,单击返回的链接,有一些链接会跳转到 404 页面。实际上这些链接是真实存在的,可以直接访问这些链接,但通过搜索框跳转访问就是不行。
只有一部分链接失效,另一部分链接是正常的。
排查过程#
这个问题是驻场 SE 报告的。在他驻场的那段时间里面,需要经常阅读官网文档辅助日常工作。由于 Rancher 中文文档的目录层级比较深,通过导航栏和目录找文档会耗费很多时间。所以他就用了搜索框输入关键字,找到他想要看的文档。
这个问题第一次出现的时间点是 2020 年 8 月,正好这段时间 Rancher 中文文档的网址在切域名,从 https://rancher2.docs.rancher.cn/ 切换到 https://docs.rancher.cn/。 切换域名之后,没有去更新 DocSearch 的配置信息,导致失效。去更新了之后,问题就解决了。
原本以为到这里之后,问题就结束了,但是 2020 年 11 月 这个问题又出现了,搜索框返回的 Rancher 2.5 文档链接失效。
解决问题#
有了上次的翻车经验,这次还是一样的处理方式:首先是把 8 月份客服帮忙解决问题的邮件回复翻了出来,找到他修改的代码和提交的 PR,照葫芦画瓢改一个再交上去。然后是跟现在对接的客服沟通,如何生成新的 sitemap.xml,所幸 DocSearch 提供了插件和详细的操作说明,操作起来也不太难。
在第一步的时候出现了一个小插曲:8 月份客服帮忙解决问题的邮件回复里面带着他提交的 PR 链接,而顺着链接找过去对应的代码库,找不到 rancher 对应的 rancher.json 文件。找过去之后我一度怀疑是不是找错了地方,直到发现最上方有一行小字:我们客户太多了,只能够显示前 1000 位客户的配置文件,按字母 a~z 排序,例如 a.json ...一直到 z.json,后面还有 2000 多位客户的配置文件无法在页面显示。
先 git clone 到本地看看再说,一看果然有 rancher.json 文件,上面配置的链接还是旧的,于是就把链接替换为新的,然后交了个 PR,等审核和合入。
然后在第二步的时候按照 DocSearch 提供的说明,首先在命令行界面 cd 到文档所在的文件夹,运行以下命令添加 sitemap 插件:
yarn add @docusaurus/plugin-sitemap然后在docusaurus.config.js里面添加了以下代码:
plugins: [ [ "@docusaurus/plugin-sitemap", { cacheTime: 600 * 1000, // 600 sec - cache purge period changefreq: "weekly", priority: 0.5, trailingSlash: false, , ],在第一步提交的 PR 合入 DocSearch 的 master 分支后,将第二步的修改合入到 Rancher 中文文档的 master 分支,上线生产环境之后,搜索框的问题就解决了。
复盘和回溯#
根据时间线来看,导致问题第二次的 PR 应该出现在 2020 年 8~12 月,涉及 docusaurus.config.js 的修改。8 月份有 1 个修改 docusaurus.config.js 的 PR,修改的原因是百度统计插件失效了,我们看 plugins 的时候发现没有百度统计插件,反而有一坨这个玩意。
plugins: [ [ "@docusaurus/plugin-sitemap", { cacheTime: 600 * 1000, // 600 sec - cache purge period changefreq: "weekly", priority: 0.5, trailingSlash: false, , ],我们误以为它是没用的,就把这段代码删除了,替换为百度统计插件:
plugins: ["@docusaurus/plugin-baidu-analytics"],此刻我们修复了百度统计插件失效的问题,同时在无意中引入了搜索框失效的问题。
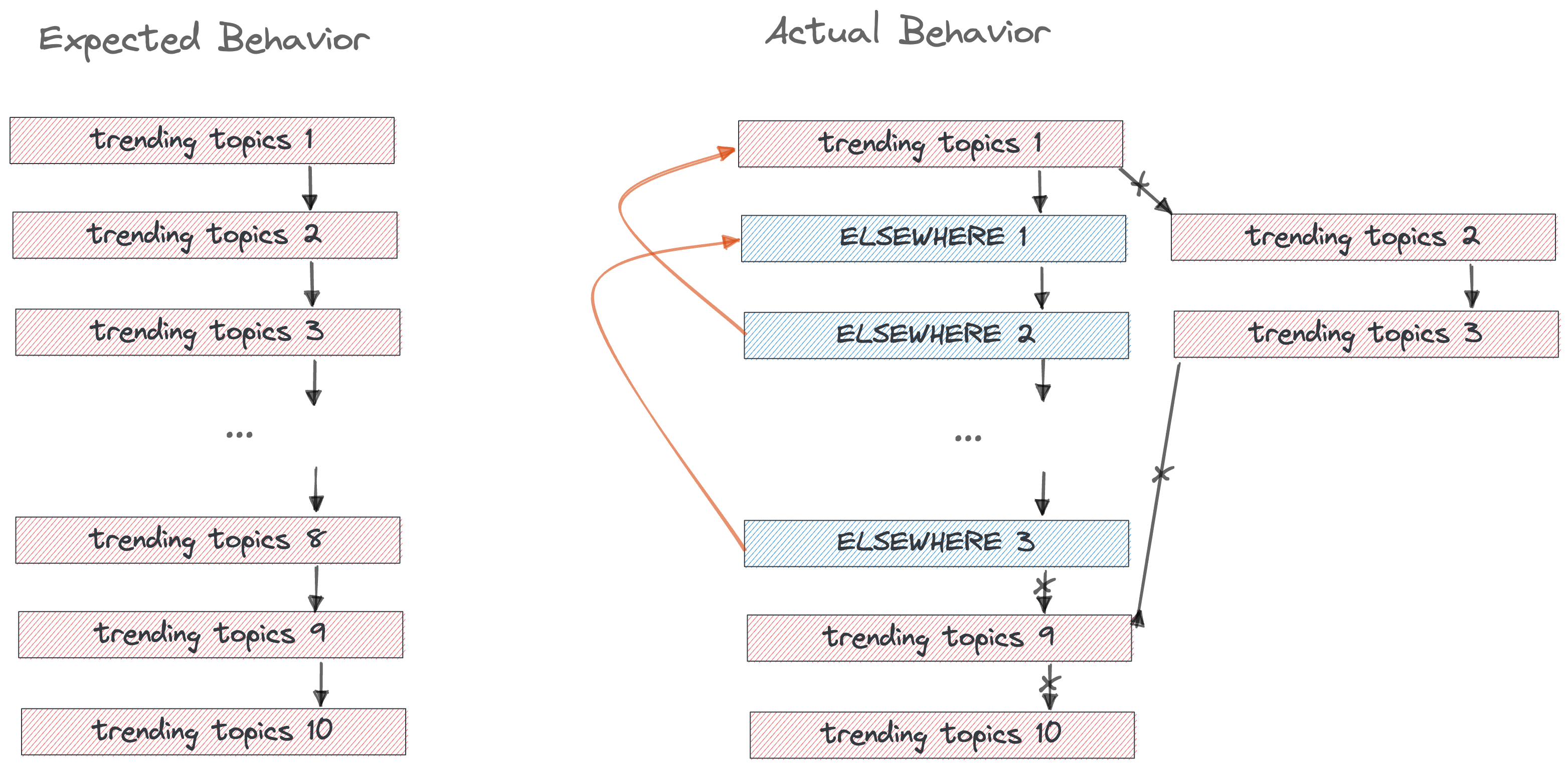
根据问题现象来看,搜索框能够正常返回所有 8 月之前添加的文档页面,而 8 月份之后删除的页面不会消失,8 月份之后新增的页面不会显示。恰好也印证了上述的猜测。
也就是说,这段时间实际发生的事情是这样的:
2020 年 8 月:误删除搜索框相关代码,导致 8 月之后更新的文档和搜索框返回的结果对应不上。Algolia 客服在他们的代码库中修改了 Rancher 的网页链接,然后在 Rancher 搜索框里面试了一下,实测返回结果有效,则认为所有返回结果都有效,然后告诉我 it works now,那么我也认为 Algolia 官方的人是对的。实际上误删除相关代码之后只能通过重新插入代码才会让搜索框完全生效。
2020 年 9~10 月:新增和删除的文档信息无法同步至 Algolia。
2020 年 11 月:发现问题根因并重新插入代码,最后问题得以解决。
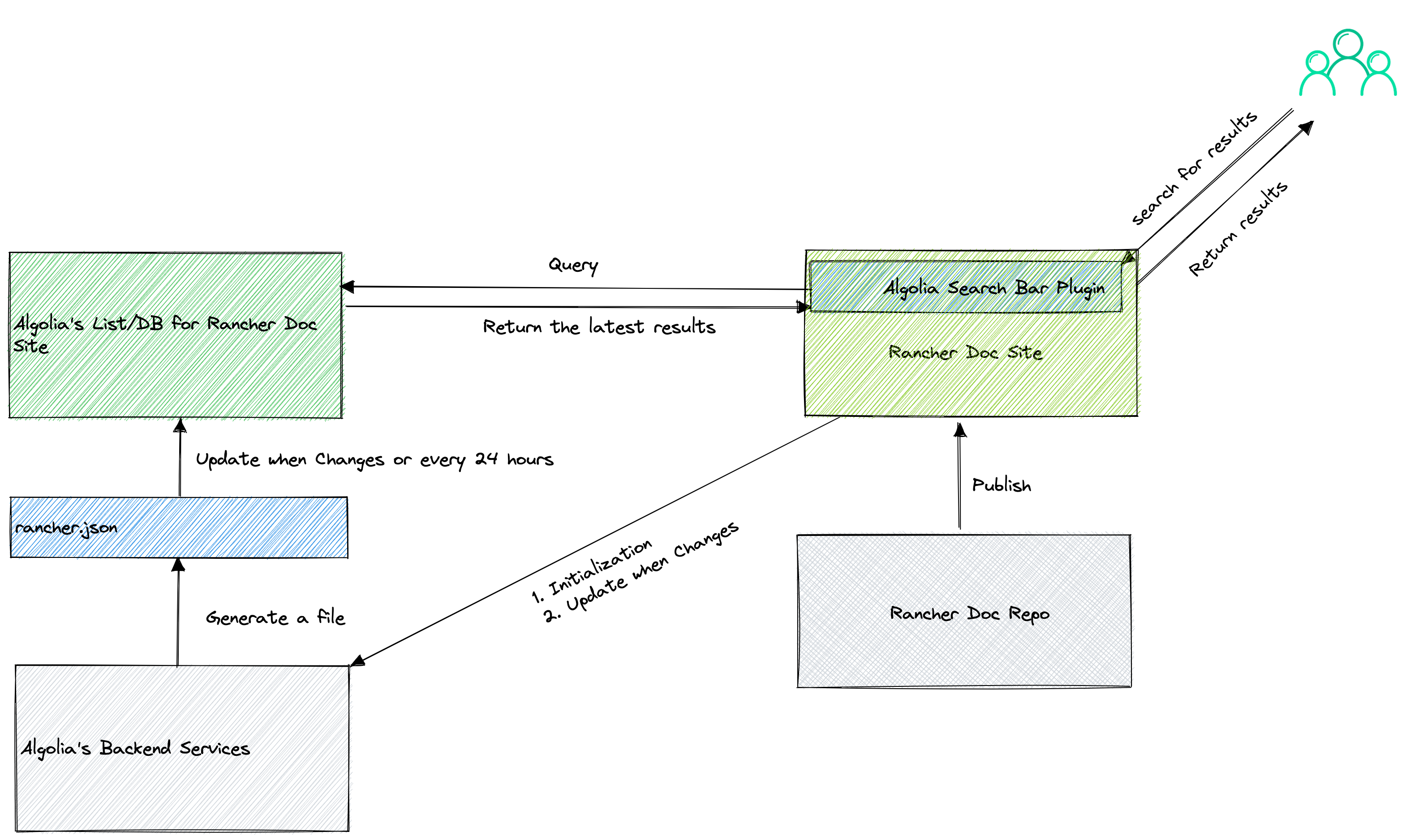
Algolia 的实现原理#
从邮件交流和实测结果看,Algolia 的实现原理是这样的:
时效性:每隔 24 小时爬取一次网站上面的所有链接,以获取在过去的 24 小时内网站的修改。换句话说,需要 24~48 小时之后,搜索框才会更新新增和删除的文档链接。具体的表现为:新增的文档链接需要 24~48 小时之后才会出现在搜索框的返回结果内,而删除的文档链接需要 24~48 小时之后才会从搜索框的返回结果消失。
需要在
docusaurus.config.js添加配置信息才会生效。删除这些配置信息之后,已有的结果不会失效,但是 Algolia 不能获取到增量变化的文档和页面。具体表现为,一部分失效了,另一部分还是正常的。